The UNIX® Operating System:
A Robust, Standardized Foundation for Cluster Architectures
Executive Summary
Do information systems consumers, suppliers and industry analysts ever agree? About clustering the answer is "Yes!" The consensus is that cluster architectures provide solutions that offer high performance, highly available and scalable systems, both for current and future information systems. Further, the standardized, state-of-the-art UNIX operating system provides the best foundation for clustering architectures both today and for years to come.
A cluster is a set of computers harnessed together to present a single server resource to applications and to users. Cluster architectures offer significant benefits, including higher performance, higher availability, greater scalability and lower operating costs. Cluster architectures are in place today for applications that must provide continuous, uninterrupted service. With redundancy designed in to all subsystems — processing, storage, network, cooling, power — cluster architectures can offer various levels of reliability. In addition, cluster architectures can be scaled smoothly to provide for increasing system performance. System architects can aggregate machines of different capacities in clusters of different sizes to target small, mid-size and very large system needs. Costs are reduced because clustering exploits low-cost, high-performance hardware. Moreover, a cluster of UNIX systems provides the same standard UNIX system environment that is used for existing applications. Finally, clustering allows system managers, developers and maintainers to field new technologies easily, integrate legacy systems and work in a uniform, familiar environment.
A cluster can be only as robust as the operating environment upon which it is based. The 64-bit UNIX system, for example, provides direct access to vast amounts of memory and storage that clusters require. Other UNIX system strengths, including its directory services and security subsystems, are crucial for synchronizing activities across a set of cooperating machines. As a result, cluster architectures built upon the UNIX system are the most popular in the marketplace. Analysts measure the UNIX system cluster advantages not in percentages, but rather orders of magnitude. When both high availability and high performance are required, then UNIX system clusters are the only choice.
This white paper examines cluster architectures with a special emphasis on the role that the UNIX system plays in enabling a collection of machines to work together in a reliable, scalable and cost-effective manner.
Cluster Architectures
Definition and history
A cluster architecture interconnects two or more computers using additional network and software technology to make a single virtual or logical server. From a technology point of view, cluster architectures provide the opportunity for system architects to link together powerful UNIX systems into even more powerful servers. And, since there are multiples of each component in a cluster, it is possible for the virtual server to continue to process information when a components fails or when system operators choose to maintain one component of the cluster.
Cluster architectures are not new to information system planners. Since the early 1980s, several suppliers have offered cluster systems based on proprietary operating environments. Best known perhaps is Digital Equipment Corporation’s (now Compaq) use of clustering to provide scalability and a uniform application environment for its VAX family of computers. In its day, the performance spectrum from a micro-VAX, through the core VAX line, and on to VAX clusters was the broadest in the industry.
The cluster architecture is one of several ways to exploit parallel processing - the harnessing of several processors to work on one or more workloads. Other parallel approaches include symmetric multiprocessing (SMP), nonuniform memory access (NUM) and massively parallel processing (MPP), which are different methods aimed at building more powerful computers with multiple microprocessors. Fault tolerant (FT) systems exploit parallel processing as a way to achieve greater reliability due to complete redundancy of components.
A cluster architecture may use as building blocks either computers built with single processors, or computers with designs such as SMP, NUMA and MMP. That is, clustering architectures aggregate computing machines whereas SMP, NUMA and MMP are architectures used within the machine.
Fault tolerant systems are built of independent, redundant subsystems, while clusters are built of independent, replicated subsystems. The redundant subsystems in a fault tolerant architecture are immediately available should the primary system fail, but do not under normal conditions assist the primary system in handling the processing load. The replicated subsystems that constitute a cluster provide high availability and also take a share of the workload. This distinction between redundant and replicated subsystems is the reason that cluster architectures enjoy price/performance advantages over fault tolerant designs.
Each of these approaches to system design aims to improve system performance, system reliability, or both. Figure 1 below summarizes the relationship of alternative designs on scalable performance and availability. As Figure 1 shows, clustering architectures can be designed to provide both broad scalable performance and high availability.
Figure 1: Scalable Performance (Y) vs. Availability (X) for Monolithic, SMP, MPP, FT and Clustering Systems
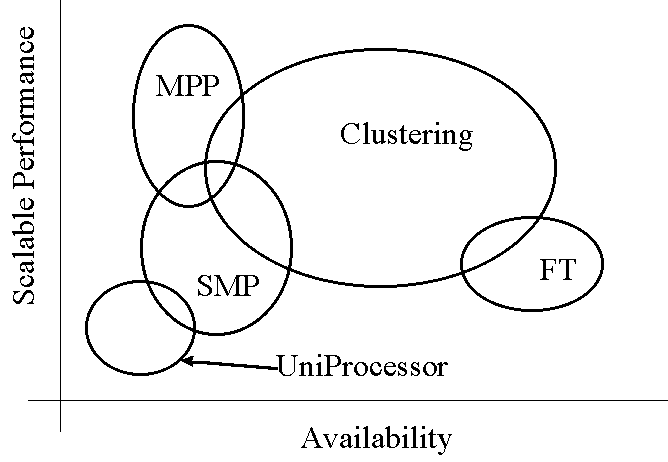
In summary, a cluster is a group of computers linked to provide fast and reliable service. Cluster technologies have evolved over the past 15 years to provide servers that are both highly available and scalable. Clustering is one of several approaches that exploits parallel processing — the use of multiple subsystems as building blocks.
Benefits
Cluster architectures provide three primary benefits: high availability, scalability and a lower cost of ownership.
High availability is defined as the capability of a computing resource to remain on-line in the face of a variety of potential subsystem failures. Failure of a power supply, for example, may cripple a processor or disk storage systems. Failure of a network access interface may isolate a subsystem from its users. Routine maintenance to upgrade an operating system or application may demand that a subsystem be taken off-line. In a monolithic system (vs. a cluster), each of these events would interrupt service.
As Figure 2 shows, at every level of a cluster architecture, subsystems are replicated. Either failures or routine maintenance activities trigger failover processes — steps are taken by the surviving subsystems to pick up the load.
Figure 2: Cluster Architectures Support Availability

An alternative approach to gaining greater availability is a fault tolerant architecture. All critical subsystems in a fault tolerant system are redundant so that in the case of a subsystem failure, a "hot spare" is immediately available. Two or more power supplies, cooling systems, disk storage and central processing units are available and running at all times.
The fault tolerant approach is expensive, however. In order to guarantee reliability, users essentially purchase several computing subsystems, only one of which carries the workload at any one time. Second and subsequent systems shadow processing and mirror the storage of data, without contributing to the overall capacity of the system.
High availability for cluster architectures works differently. For example, five clustered computers may divide the load for a set of critical applications. Under normal circumstances, all five computers contribute toward processing the tasks at hand. Should one of the computers fail, then the four remaining computers pick up the load. Depending on the load at the time of the failure, performance will drop no more than 20%. And, switching the load of the failed machine to other machines usually takes a short period of time.
For many enterprise applications, the cluster approach is superior. A short delay for failover and slightly slower response times are entirely acceptable, particularly when costs are substantially lower (than the FT approach). In addition, the downtime generally allotted to maintenance can often be scheduled for times when enterprise demands on the application suite are low.
Scalability is the ability to vary the capacity of a system incrementally over as broad of a range as possible. Monolithic systems are scaled by adding or subtracting components to the computer (e.g., additional memory, disks, network access interfaces, processors) or by shifting to a different computer entirely.
Cluster architectures are scaled in two ways. First, designers select the monolithic systems that become the building blocks for the cluster. In the case of UNIX system clusters, these building blocks range from inexpensive and less powerful CISC computers to SMP RISC machines of significant capacity. Second, designers choose the number of computers in the cluster. By selecting both the size and number of building blocks, designers of cluster architectures achieve a very wide and smooth capacity range.
Cluster architectures lower the cost of ownership in several ways. First, the standardized UNIX system has established itself as cost-effective. That is, commodity UNIX system servers are themselves a bargain, and when a cluster of inexpensive machines competes with a conventional, proprietary mainframe, then cost savings are even more dramatic.
Secondly, a UNIX system cluster provides a uniform, standard UNIX operating system for the "virtual server." As a result, the secondary savings in software can be realized as well. For enterprises with legacy systems — that is, for all enterprises — this means that an SAP installation or an ORACLE, SYBASE or INFORMIX database can be migrated to a cluster without strenuous effort. All the portability and interoperability of the UNIX system remains available to the cluster.
Thirdly and most importantly, a UNIX system cluster exploits the same core skills needed in UNIX system development and management that enterprises have been cultivating over the past 20 years. Rather than maintaining different staff skills in support of departmental, divisional and enterprise platforms, the scalable cluster architecture allows the same skilled staff to work across the enterprise. Mission-critical systems can be hosted on the UNIX system clusters as well, avoiding the cost of maintaining proprietary fault tolerant environments. In addition, many single-system management tools are being integrated with cluster interconnect software to create a unified management system for the enterprise.
In summary, cluster architectures address the three most important challenges facing enterprise information systems. Clusters allow designers to provide high availability in proportion to the costs of downtime for enterprise applications. Cluster architectures scale smoothly over a vast performance and capacity range. Finally, UNIX system clusters in particular are less expensive to own and operate due to the convergence of low-cost components, a highly competitive software marketplace and the availability of technicians familiar with the UNIX operating system.
The Technology of Cluster Architectures
The key technology of clustering broadly stated is the interconnection among component computers — ordinarily called nodes in the cluster. Additional software and hardware is required in order to interconnect the nodes. Interconnect technology is responsible for coordinating the work of the nodes and for effecting failover procedures in the case of a subsystem failure. Interconnect technology is responsible for making the cluster appear to be a monolithic system and is also the basis for system management tools.
Interconnect technology
The foundation for clustering is an interconnection aimed at coordinating the activities of the nodes. Cluster interconnections are often a network or a bus dedicated to this purpose alone. High-performance cluster architectures require a network with high bandwidth, often in the 100 MBps range. Loosely coupled clusters may depend on simple twisted-pair linkages between serial ports. The exact requirements of the network vary with the design objectives for the cluster.
Shared vs. distributed storage
Clusters may be designed with shared persistent storage or with distributed persistent storage. In a shared storage architecture, the interconnection among nodes provides access to a common set of disks. The use of redundant array of inexpensive disks [RAID] technology for storage is conventional. Nodes operate in a shared address space, with software managing locks so that processes running in parallel do not disrupt each other’s work. Shared storage makes better sense for systems that manage large shared databases and for systems that can be concentrated in a single location.
Figure 3: Cluster with Shared Storage
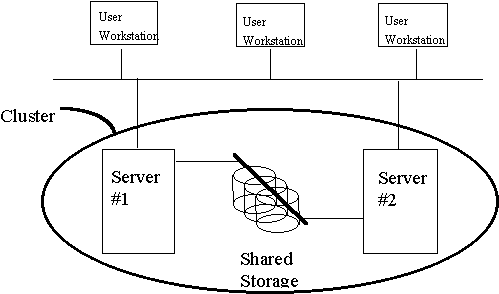
In a distributed storage architecture, each node has access to its own disk storage. When information needed by one node is managed by another, then access is provided by message-passing mechanisms. Message-handling processes that distribute data and synchronize updates are the responsibility of the interconnect software. Distributed storage makes better sense for systems that access independent sets of data and for systems that are dispersed more widely across distance.
Cluster architectures are quite flexible and, as a result, it is possible to mix both shared and distributed storage when necessary. Such an architecture would strongly suit an enterprise with a corporate headquarters where large data warehouses are managed (with shared storage) and with offices around the globe that operate autonomously on a day-to-day basis (with distributed storage).
Shared vs. distributed memory
Main memory may be shared or distributed in a cluster architecture. Most commonly, main memory is distributed and communication among nodes is accomplished by message-passing via the interconnect network. Distributed main memory is favored when applications are able to run within the capacity of any of the independent nodes.
Figure 4: Shared Main Memory
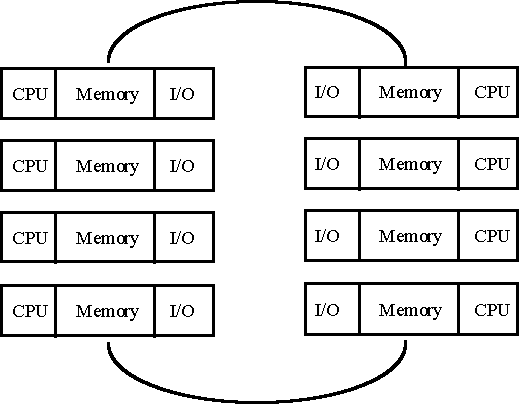
Higher performance can be achieved by unifying access to main memory for all nodes in the cluster, as shown in Figure 4. This is ordinarily accomplished with a second dedicated network that provides a shared, high-speed bus. Clusters operating with shared memory are very similar to SMP computers.
How failover works
Failover is the ability of a cluster to detect problems in a node and to accommodate ongoing processing by routing applications to other nodes. This process may be programmed or scripted so that steps are taken automatically without operator intervention. In other cases, such as taking a node out of operation for maintenance, the failover process may be under operator control.
Fundamental to failover is communication among nodes, signaling that they are functioning correctly or telegraphing problems when they occur. The metaphor most commonly used is of a node’s "heartbeat." Namely, each computing machine listens actively to make sure that all of its companions are alive and well.
When a machine fails, cluster interconnect software takes action. In the simplest failover situations, an operator is alerted. More sophisticated cluster software reacts to the problem by shifting applications and users automatically and quickly reconnects to one or more healthy members of the cluster. Journals may be necessary to bring an application up to its current transaction with integrity. Databases may need to be reloaded. All of this functionality is part of the cluster architecture interconnect software.
The catastrophic failure of an entire node is one event to which the cluster management environment must respond. There are several other potential problems to be considered as well. For example, a node may be able to process information, but due to the failure of a network interface (e.g., an Ethernet card), the node cannot communicate with its users. Alternately, it may be that one of the disks in a RAID subsystem fails. High-speed access links to shared storage may break down, or telecommunication links to distant, distributed storage may become unavailable.
Designers of cluster architectures must weigh the likelihood and cost of each of these categories of failure and prepare failover contingencies to manage them appropriately. In this way, the resulting cluster is the right solution for the business problem at hand.
Cluster Architectures in Action
Cluster architectures have demonstrated astonishing performance, both in speed and reliability.
High availability
Availability is measured in percentage, and 100% availability is the best that can be expected. Monolithic systems can be expected to perform 99% of the time. However, 1% downtime translates to 90 hours in a year, or about 3.5 days. For many businesses, 3.5 days without information system support would be either catastrophic, or at least very expensive. As a general rule, two "9s," or 99% translates to a week of downtime. Three "9s" equates with days, four "9s" with hours and five "9s" with minutes.
Fault-tolerant systems can improve reliability to 99.999%, or five minutes a year. At this level of system reliability, it is far more likely that extrinsic factors will interrupt service. Wide-scale power or communication failure is one kind of extrinsic factor; application software reliability is another.
Cluster architectures can be tuned in accordance with the cost of downtime and may be designed to operate in the 99.5% to 99.99% range. The degree of performance degradation and the time lapse in service are parameters in cluster design. This flexibility is a distinct advantage for most enterprises.
Scalability
Scalability is achieved by aggregating the power of a number of independent computers. UNIX system-based cluster architectures vary in scaling with top echelon competitors joining together up to eight machines. When the eight nodes or more are themselves SMP computers containing as many as 14 or more processors, the total number of processors rises to more than 100. As a result, top-end performance of UNIX system clusters is extraordinary.
Important implications for scalability at lower ranges of performance exist as well. With the clustering approach, the local grocer need not accept 99% availability for the store’s mid-size server. Rather, a cluster of smaller computers can replace that single server, scale to the smaller requirements of the store and also provide high availability. This is a huge step forward as consumers along a broad performance spectrum can greatly benefit from high availability.
Case studies
UNIX system suppliers have collected many case studies of cluster architectures in daily use. Here are three typical examples:
Acxiom Corporation is one of the world’s largest suppliers of data and market intelligence. Their systems manage 250 terabytes of consumer data alone, and their data center is a 4-acre complex. The basic architecture for Acxiom is the UNIX-based cluster furnished by Digital Equipment Corporation (now Compaq).
"We start with a modest system configuration," says Greg Cherry, an application development consultant at Acxiom, "knowing that there’s plenty of headroom on the AlphaServer 8400 - as well as clustering if the data warehouse grows beyond the capacity of a single system."
Acxiom’s first AlphaServer managed 800 gigabytes of data, and over a nine-month span, its capacity has grown to 2 terabytes. "Our customers understand this incremental growth path saves money and minimizes risk, because we’re investing in upgrades only when the need is proven," Cherry explains.
Acxiom’s use of clustering focuses primarily on scalability and cost savings.
The challenge at Gemeente Maastricht and Gemeente Amersfoort, both Dutch government organizations, is availability. In order to achieve a 99.9% level, these organizations turned to Unisys Corporation, which prescribed a cluster based upon UnixWare from Santa Cruz Operations (SCO) and Unisys interconnection software called Reliant HA. Five Aquanta servers, which are SMP machines using Pentium Pro processors, provide the foundation for database and application services.
To further defend against disaster, these clusters are interconnects to redundant hit backup systems in disaster centers. High-speed interconnection is provided by replicated fiber-optic connections. When idle, the backup systems provide an environment for system testing, data backup and data warehousing.
A fault tolerant architecture was rejected on grounds of higher costs. In particular, these government agencies exploited the uniform UNIX system environment in order to obtain packaged software that was unavailable under proprietary fault tolerant systems.
CVS (Consumer Value Store) is a $13 billion pharmacy drug chain serving 27 American states with over 4,000 retail stores. At the heart of CVS information systems are Siemens/Pyramid Reliant RM1000 cluster servers. These cluster systems support the day-to-day operations of CVS by providing prescription validation, data warehouse for analysis of customer buying patterns and supply chain management. Prescription validation is available 7 days a week, 24 hours a day, and is an online transaction processing application.
CVS cluster applications, which are all based on the UNIX system, harness over 200 processors and address 7 terabytes of disk storage. Oracle is the database management software provider for these applications.
Cluster architectures provide CVS with critical business systems that allow the enterprise to operate in an extremely competitive business environment. A highly available repository of patent data and timely access to customer data are key success factors for CVS operations.
These three examples are drawn from a vast reservoir of experience in designing and fielding sophisticated cluster architectures based on the UNIX system. The three examples show how sharply contrasting goals ¾ scalability versus availability ¾ can be achieved within the cluster architecture framework.
Cluster Technology in the Next Millennium
The cluster architecture is the way forward for system architectures. Clustering techniques are providing the next leap forward in system performance, reliability and cost. The UNIX system today enjoys a significant technology and market lead. UNIX system-based cluster architectures will continue to hold this lead in the marketplace for many years to come.
Advances in clustering technology
Interconnect hardware technology will continue to be enhanced, with improvements expected both for the bandwidth of communication among members of a cluster and also for the distances spanned by high-speed networks. Increased use of fiber-optic interconnections, for example, will increase the speed with which cooperating machines intercommunicate and thus their ability to share data and to failover very rapidly.
SMP and NUMA technologies will provide cluster architectures with more powerful nodes. As we have noted, the extraordinary power of clusters is due in significant measure to the multiplicative leveraging of more machines, each of which is more powerful. As SMP machines move from 8 to 64 and on to hundreds of processors, and as cluster size increases move from 4 to 8 and on to 96 machines, then the overall capacity of the cluster grows from 32 to well over 500 processors.
UNIX system suppliers will be extending the limits of disaster recovery by designing systems that are disaster tolerant. Just as high availability aims to minimize downtime, disaster tolerant systems minimize recovery time. Traditional backup-to-tape systems provide recovery times measured in days. Cluster architectures designed to thwart disaster can minimize recovery time to minutes, or if the business application warrants, to seconds.
UNIX system-based cluster architectures profit from the continuing evolution of the UNIX operating system. For example, UNIX 98 offers the only consistent, standards-based method of handling threads and real-time, enabling application developers to use one set of interfaces no matter which manufacturer’s UNIX 98 system is purchased. As the UNIX operating system evolves to handle new kinds of data and communication, then UNIX system clusters will automatically deliver additional performance, scalability and cost of ownership benefits of the underlying platform. Continuing progress in areas such as object- and message-oriented middleware, for example, will provide UNIX system buyers with an enriched environment for routing information among cooperative machines. In addition, all the major technology developments, such as Java™ , Object Request Brokers and Open Network Computers are being developed on, or to work with, the UNIX system.
Dynamic in the clustering marketplace
There is an additional important market dynamic that is orthogonal to specific technology advances for clustering architectures. Namely, in the case of UNIX system-based systems, there exists a set of suppliers who are keenly competitive with one another. Because UNIX systems from all vendors are guaranteed to implement a single consensus set of standards, buyers cannot be "locked in." Rather, they compete each year by providing the best reliability, service, support, functionality and value for money. As a result of this competition, UNIX system suppliers provide the most sophisticated, cost-effective cluster architectures available.
Suppliers of proprietary operating environments have, over the years, failed to create competition for any technologies contiguous with the operating system. The problem is that independent software suppliers are constantly threatened by the risk of functional integration. That is, functionality developed and fielded by independent software suppliers is often assimilated into the proprietary product. Further, since proprietary system suppliers may change underlying operating system behavior, it is therefore much more difficult for independent software vendors to build quality products and maintain them over time, which ultimately increases the cost to the buyer.
Summary and Conclusions
The cluster architecture provides the blueprint for building available systems, now and in the future. Cluster interconnect technology has been refined over the past 15 years and is being deployed. In fact, innovative enterprises have successfully applied cluster solutions to mission-critical applications in order to gain high availability without the cost of fault tolerant systems.
Cluster architectures depend heavily on the operating systems resident on each node. This is part of the reason that UNIX system-based cluster architectures are so much better, faster and more reliable than proprietary products. In addition to the advantages of a robust, standard operating environment, the marketplace for the UNIX system is also vibrant. Fierce competition has forged strong product lines from all UNIX system suppliers. As such, UNIX systems are far ahead in terms of functionality, scalability and reliability.
References
Digital Equipment Corporation. 1997. TruCluster Software: Highly Available and Scalable Solutions on DIGITAL UNIX Systems.
Heijma, Ad. 1998. Personal communication. (Ad Heijma is a Unisys account representative based in the Netherlands.)
Pfister, G. F. 1998. In Search of Clusters: The Coming Battle in Lowly Parallel Computing (Second Edition). Upper Saddle River, NJ: Prentice-Hall PTR.
Willard, C. G. 1996. Digital’s Memory Channel Technology Brings Clusters into the 21st Century. Framingham, MA: International Data Corporation.
UNIX® is a registered trademark of The Open Group.